This summer, I have worked in the development of textual modules in FastAI.jl for GSoC’22 under the NumFOCUS organization. The goal of the project is to develop textual pipelines in FastAI.jl (for text classification and text generation to be specific).
The project is divided into two parts:
- Text Classification Pipeline: This is the first part of the project, where I have developed a text classification pipeline in FastAI.jl. This pipeline is based on IMDb dataset.
- Text Generation Pipeline: This is the second part of the project, where I have developed a text generation pipeline in FastAI.jl.
The project page can be found here.
Text Classification Pipeline
The dataset being used here is IMDb large dataset. This contains 50,000 reviews out of which 25,000 were for training and 25,000 are for testing. The dataset is divided into 25,000 positive reviews and 25,000 negative reviews. The dataset is available here. The goal of this part of the project is to develop a classification pipeline around this dataset.
Text Classification Dataset Recipe
The recipe implemented for IMDb dataset can be used for any other text dataset that has the same folder structure as IMDb. The input is wrapped up in a Paragraph block and the output is wrapped up in a Label block. Paragraph is nothing but a text paragraph.
julia> using FastAI, FastText
julia> data, blocks = load(datarecipes()["imdb"])
julia> getobs(data, 1), numobs(data)
(("Story of a man who has unnatural feelings for a pig. Starts out with a opening scene that is a terrific
example of absurd comedy. A formal orchestra audience is turned into an insane, violent mob by the crazy
chantings of it's singers. Unfortunately it stays absurd the WHOLE time with no general narrative eventually
making it just too off putting. Even those from the era should be turned off. The cryptic dialogue would make
Shakespeare seem easy to a third grader. On a technical level it's better than you might think with some good
cinematography by future great Vilmos Zsigmond. Future stars Sally Kirkland and Frederic Forrest can be seen
briefly.", "neg"), 25000)
Text Classification Task and Encodings
The TextClassificationSingle is used to encode the input and output into a format that is acceptable by the model. The preprocessing steps for Paragraph and Label are as follows:
-
Paragraph
Sanitize: The input is first cleaned usingSanitizeencoding that cleans the inputParagraphby applyingfastaispecific encodings (adding special tokens like xxup, xxmaj, etc), removing punctuations, removing html tags, removing number etc. The output of this encoding is aParagraph(but sanitized).Tokenize: The sanitized input is the converted into tokens by leveraging theTextAnalysis.jlfunctions. The output of this enodings isTokens.EmbedVocabulary: The tokens are then converted into indices using this encoding. The output of this encoding isNumberVector. This step also introduces some special tokens like<UNK>(token id = 1) that are used to represent unknown tokens.
-
Labels
OneHot: The labels are converted to one-hot vectors using this encoding.
julia> task = TextClassificationSingle(blocks, data)
SupervisedTask(Paragraph -> Named{:target, Label{String}})
julia> td = taskdataset(data, task, Training())
julia> td[1]
([35, 3, 68, 7, 6, 130, 41, 52, 7567, 1400 … 11610, 5, 3, 16709, 3, 8050, 56, 33, 113, 3342], Bool[1, 0])
Text Classification Model
The model being used here is the AWD_LSTM, a variation on vanilla LSTM that improves performance by using various custom layers like DropConnect, WeightDropped LSTM, Varitional DropOut, DropEmbeddings, etc. The model adopts a transfer learning strategy called ULMFiT that uses a pretrained language model to fine-tune the model on the target dataset. The language model is trained on a large corpus of text (Wikipedia-103, etc) and the target model is trained on the target dataset.
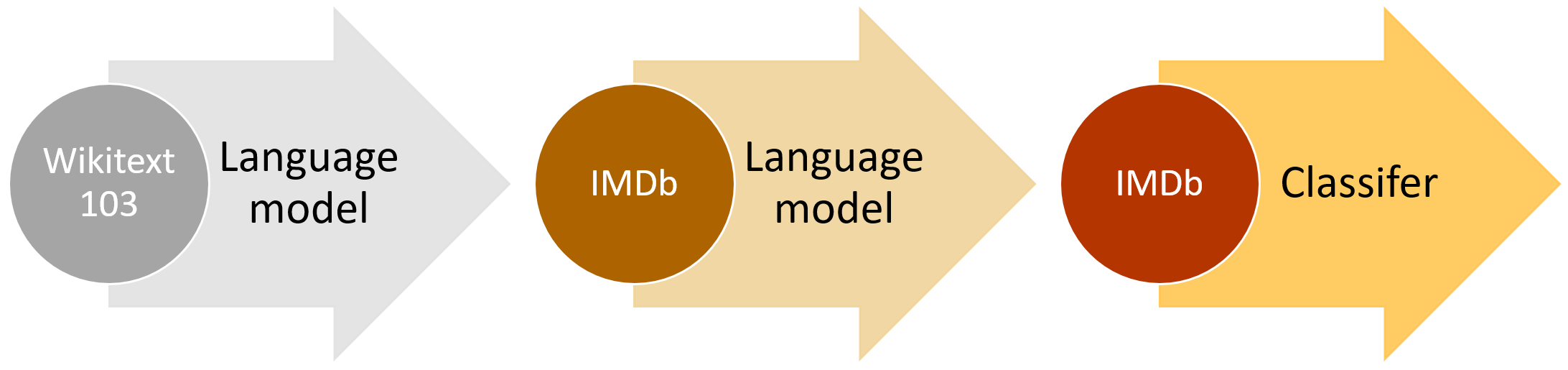
julia> language_model = FastText.LanguageModel(false, task)
julia> typeof(language_model)
LanguageModel{Vector{String},
Chain{Tuple{
FastText.DroppedEmbeddings{Matrix{Float32}, Float32, Vector{Float32}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}},
Flux.Recur{FastText.WeightDroppedLSTMCell{Matrix{Float32}, Vector{Float32}, Matrix{Float32}, Tuple{Matrix{Float32}, Matrix{Float32}}}, NTuple{4, Matrix{Float32}}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}},
Flux.Recur{FastText.WeightDroppedLSTMCell{Matrix{Float32}, Vector{Float32}, Matrix{Float32}, Tuple{Matrix{Float32}, Matrix{Float32}}}, NTuple{4, Matrix{Float32}}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}},
Flux.Recur{FastText.WeightDroppedLSTMCell{Matrix{Float32}, Vector{Float32}, Matrix{Float32}, Tuple{Matrix{Float32}, Matrix{Float32}}}, NTuple{4, Matrix{Float32}}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}},
Base.Fix2{FastText.DroppedEmbeddings{Matrix{Float32}, Float32, Vector{Float32}}, Bool},
typeof(softmax)}
}
}
The text classification model takes the initial layers of the language model and adds a classifier on top of it. The classifier consists of dense layer, batch norm, dropout and a final dense layer with softmax activation.
julia> classifier = FastText.TextClassifier(language_model)
julia> typeof(classifier)
FastText.TextClassifier{Vector{String},
Chain{Tuple{
FastText.DroppedEmbeddings{Matrix{Float32}, Float32, Vector{Float32}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}},
Flux.Recur{FastText.WeightDroppedLSTMCell{Matrix{Float32}, Vector{Float32}, Matrix{Float32}, Tuple{Matrix{Float32}, Matrix{Float32}}}, NTuple{4, Matrix{Float32}}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}},
Flux.Recur{FastText.WeightDroppedLSTMCell{Matrix{Float32}, Vector{Float32}, Matrix{Float32}, Tuple{Matrix{Float32}, Matrix{Float32}}}, NTuple{4, Matrix{Float32}}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}},
Flux.Recur{FastText.WeightDroppedLSTMCell{Matrix{Float32}, Vector{Float32}, Matrix{Float32}, Tuple{Matrix{Float32}, Matrix{Float32}}}, NTuple{4, Matrix{Float32}}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}}}
},
Chain{Tuple{
FastText.PooledDense{typeof(identity), Matrix{Float32}, Vector{Float32}},
BatchNorm{typeof(relu), Vector{Float32}, Float32, Vector{Float32}},
Dropout{Float32, Colon, Random.TaskLocalRNG},
Dense{typeof(identity), Matrix{Float32}, Vector{Float32}},
BatchNorm{typeof(identity), Vector{Float32}, Float32, Vector{Float32}},
typeof(softmax)}
}
}
Text Classification Task Model and Learner
The TaskModel is used to wrap the model and the task together. This TaskModel takes in a task and the backbone (LanguageModel in this case). The Learner is used to train the model. The Learner takes the TaskModel, the data, the loss function, the optimizer, the metrics and the callbacks.
julia> model = FastAI.taskmodel(task, FastText.LanguageModel(false, task))
Before loading the enoded data into the model, we need to change the structure of the data. Currently, the data is of the format ([NumberVector, Bool[1, 0]]). We need to utilise the idea of batches for training. Since each sample is of different length, we need to pad the samples to the same length batch-wise by using another special token <PAD> (token id = 2). Each sample of a single batch is the tokens for the current time step.
julia> batches = FastText.load_batchseq(data, task, batch_size = 4)
julia> batches[1][1] # Input from the first batch
226-element Vector{Vector{Int64}}:
[38, 38, 38, 38] # first tokens of first timestep for 4 sequences in the batch
[3, 3, 3, 3]
[532, 1250, 239, 15]
[397, 5, 8, 17]
[17, 12, 3, 236]
[3, 2593, 530, 35]
[953, 9, 3, 13]
[288, 295, 421, 461]
[8, 58, 486, 23]
[77, 137, 9, 4]
⋮
[2, 7, 2, 2]
[2, 3, 2, 2]
[2, 128, 2, 2]
[2, 287, 2, 2]
[2, 155, 2, 2]
[2, 12, 2, 2]
[2, 285, 2, 2]
[2, 9, 2, 2]
[2, 2074, 2, 2]
julia> batches[1][2] # Output from the first batch
2×4 OneHotMatrix(::Vector{UInt32}) with eltype Bool:
1 . 1 1
⋅ 1 ⋅ ⋅
Next we’ll split the input data into train and validation sets using splitobs.
julia> train, valid = splitobs(data, at = 0.8)
Finally, we can get a Learner for the model and train it.
julia> learner = Learner(model, Flux.Losses.logitcrossentropy, callbacks=[Metrics(accuracy)]; data=(td, vd))
julia> fit!(learner, 1)
Epoch 1 TrainingPhase(): 100%|██████████████████████████| Time: 0:08:05
┌───────────────┬───────┬─────────┬──────────┐
│ Phase │ Epoch │ Loss │ Accuracy │
├───────────────┼───────┼─────────┼──────────┤
│ TrainingPhase │ 1.0 │ 0.70231 │ 0.5 │
└───────────────┴───────┴─────────┴──────────┘
Epoch 1 ValidationPhase(): 100%|████████████████████████| Time: 0:00:26
┌─────────────────┬───────┬─────────┬──────────┐
│ Phase │ Epoch │ Loss │ Accuracy │
├─────────────────┼───────┼─────────┼──────────┤
│ ValidationPhase │ 1.0 │ 0.68952 │ 0.546 │
└─────────────────┴───────┴─────────┴──────────┘
Epoch 2 TrainingPhase(): 100%|██████████████████████████| Time: 0:08:05
┌───────────────┬───────┬─────────┬──────────┐
│ Phase │ Epoch │ Loss │ Accuracy │
├───────────────┼───────┼─────────┼──────────┤
│ TrainingPhase │ 2.0 │ 0.69728 │ 0.50289 │
└───────────────┴───────┴─────────┴──────────┘
Epoch 2 ValidationPhase(): 100%|████████████████████████| Time: 0:00:26
┌─────────────────┬───────┬─────────┬──────────┐
│ Phase │ Epoch │ Loss │ Accuracy │
├─────────────────┼───────┼─────────┼──────────┤
│ ValidationPhase │ 2.0 │ 0.69042 │ 0.546 │
└─────────────────┴───────┴─────────┴──────────┘
Text Generation Pipeline
This part focuses on the text generation task. We’ll train a language model on the IMDb dataset. For this we’ll use the data from the unsup folder of the dataset.
Text Generation Dataset Recipe
The dataset recipe is similar to the one used for the classification task. But the only difference is that our input data is now Paragraph and output data is also a Paragraph.
julia> path = load(datasets()["imdb"])
julia> recipe = FastText.TextGenerationFolders()
julia> data, blocks = Datasets.loadrecipe(recipe, path)
julia> blocks
(Paragraph(), Paragraph())
Text Generation Task and Encodings
The task is similar to the classification task. The only difference is that the output is now a Paragraph.
The encodings were also similar to the ones used for the classification task. The only difference is that the last OneHot is now wrapped to in a Named block with a name :target. This enables us to OneHot encode only the second block of the data, which is the target Paragraph.
julia> task = FastText.TextGeneration(blocks, data, vocab_size = 40000)
SupervisedTask(Paragraph -> Named{:target, Paragraph})
Text Generation Task Model and Learner
As already mentioned, the model used here is a LanguageModel using variuos custom layers like Embedding, Dropout, LSTM and Dense. The LanguageModel is wrapped in a TaskModel which is then used to create a Learner.
julia> model = FastAI.taskmodel(task, FastText.LanguageModel(false, task))
LanguageModel{Vector{String},
Chain{Tuple{
FastText.DroppedEmbeddings{Matrix{Float32}, Float32, Vector{Float32}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}},
Flux.Recur{FastText.WeightDroppedLSTMCell{Matrix{Float32}, Vector{Float32}, Matrix{Float32}, Tuple{Matrix{Float32}, Matrix{Float32}}}, NTuple{4, Matrix{Float32}}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}},
Flux.Recur{FastText.WeightDroppedLSTMCell{Matrix{Float32}, Vector{Float32}, Matrix{Float32}, Tuple{Matrix{Float32}, Matrix{Float32}}}, NTuple{4, Matrix{Float32}}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}},
Flux.Recur{FastText.WeightDroppedLSTMCell{Matrix{Float32}, Vector{Float32}, Matrix{Float32}, Tuple{Matrix{Float32}, Matrix{Float32}}}, NTuple{4, Matrix{Float32}}},
Flux.Recur{FastText.VarDropCell{Float32}, Tuple{Bool, Matrix{Float32}}},
Base.Fix2{FastText.DroppedEmbeddings{Matrix{Float32}, Float32, Vector{Float32}}, Bool},
typeof(softmax)}
}
}
Now we need to batch the data for speeding up the training process. We’ll use load_genseq function to do this batching. This funnction takes in the data and batches the input and pads the OneHot encoded target data with <PAD> token. This function also shifts the target by one token to the right and input by one token to the left. This is done to make the model predict the next token given the previous token.
julia> batches = FastText.load_genseq(data, task, batch_size=4)
julia> batches[1][1]
609-element Vector{Vector{Int64}}:
[40, 40, 40, 40]
[9, 3, 3, 3]
[13, 292, 62, 194]
[105, 15, 3, 299]
[191, 74, 34, 16]
[3, 16, 1120, 26]
[152, 11, 211, 13]
[3, 35, 56, 123]
[166, 7, 3, 405]
[3, 108, 69, 14]
[18, 104, 3, 8]
[51, 17, 52, 46]
[14, 9, 10, 6]
⋮
[2, 501, 2, 2]
[2, 7, 2, 2]
[2, 416, 2, 2]
[2, 14, 2, 2]
[2, 15, 2, 2]
[2, 159, 2, 2]
[2, 88, 2, 2]
[2, 6, 2, 2]
[2, 156, 2, 2]
[2, 107, 2, 2]
[2, 97, 2, 2]
[2, 12, 2, 2]
julia> batches[1][2]
609-element Vector{Matrix{Bool}}:
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 0 0 0 0; … ; 0 0 0 0; 0 0 0 0]
⋮
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
[0 0 0 0; 1 0 1 1; … ; 0 0 0 0; 0 0 0 0]
julia> batches[1][2][1]
4424×4 Matrix{Bool}:
0 0 0 0
0 0 0 0
0 1 1 1
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
1 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
⋮
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
0 0 0 0
julia> td, vd = splitobs(batches, at=0.8)
julia> learner = Learner(model, Flux.Losses.logitcrossentropy, callbacks=[Metrics(accuracy)]; data=(td, vd))
Learner()
julia> fit!(learner, 1)
Status of PRs
| Link to PR | Details | Status |
|---|---|---|
| PR #207 | Container and data block for classification data. | Merged |
| PR #245 | Classification task. | Merged |
| PR #250 | Text model integration (classification). | Not yet merged |
| PR #258 | Text generation container, task, model. | Not yet merged |
Future work
- Add support for pretraining language model with WikiText-103 dataset.
- Add support for sharing embeddings of a pretrained model for finetuning.
- Try implementing BPTT for text generation to avoid memory issue on local/colab (if possible).